MongoDB
Linux安装包方式
安装MongoDB
官网下载:https://www.mongodb.com/try/download/community-kubernetes-operator
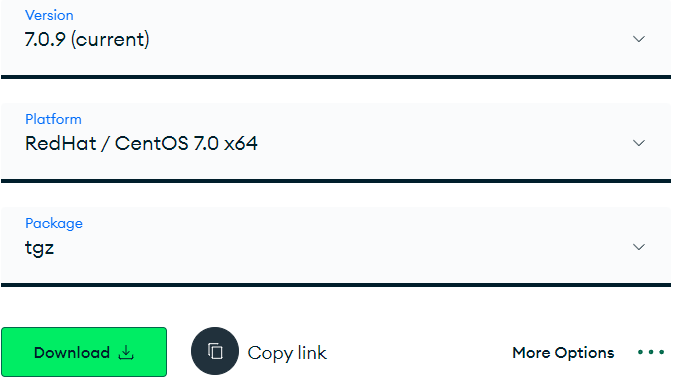
这里可以直接下载.tgz文件,然后使用工具上传至服务器
或在服务器上使用命令下载
cd /opt
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-7.0.9.tgz
tar -zxvf mongodb-linux-x86_64-rhel70-7.0.9.tgz
# 创建mongdb必要目录和日志文件
mkdir -p /usr/local/mongodb/{data,logs,etc}
touch /usr/local/mongodb/logs/mongodb.log
# 创建配置文件
vi /usr/local/mongodb/etc/mongodb.conf
#################################### mongodb.conf文件内容 ####################################
systemLog:
# MongoDB 所有日志输出的目标指定为文件
destination: file
# 日志文件的路径
# 默认情况下,MongoDB 的日志文件为 /var/log/mongodb/mongod.log
path: /usr/local/mongodb/logs/mongodb.log
# true 日志的写入方式为在指定的日志文件中追加写入
#(false 则会在指定的日志文件存放路径的同一个目录下新建日志文件记录日志)
logAppend: true
storage:
# 数据库文件存放的路径
dbPath: /usr/local/mongodb/data
# 存储引擎,这里使用的是 WiredTiger,MongoDB 3.2 版本后默认的高性能存储引擎
engine: wiredTiger
net:
# 绑定的IP地址,0.0.0.0 表示监听所有可用的网络接口
bindIp: 0.0.0.0
port: 27017
processManagement:
# 是否以守护进程(后台)模式运行MongoDB,fork为true表示后台运行
fork: true
security:
# 用户验证,默认为disabled,创建管理员账户后修改为enabled
authorization: disabled
#######################################################################################
mv mongodb-linux-x86_64-rhel70-7.0.9 /usr/local/mongodb
# 配置环境变量
vi /etc/profile
export PATH=/usr/local/mongodb/mongodb-linux-x86_64-rhel70-7.0.9/bin:$PATH
# 使配置文件生效
source /etc/profile
# 启动命令
mongod -f /usr/local/mongodb/etc/mongodb.conf
# 关闭命令,这里不需要进入mongosh
mongod --port=27017 --dbpath=/usr/local/mongodb/data --shutdown安装Mongosh
Mongosh用于本机连接Mongdb服务。
官网下载:https://www.mongodb.com/try/download/compass
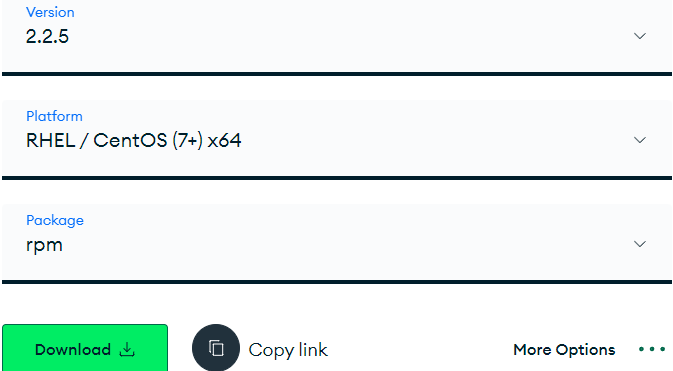
cd /opt
# 下载
wget https://downloads.mongodb.com/compass/mongodb-mongosh-2.2.5.x86_64.rpm
# 安装
rpm -ivh mongodb-mongosh-2.2.5.x86_64.rpm
#默认连接本地27017
mongosh
#指定地址和端口
mongosh --host 127.0.0.1 --port 27017
#如果配置文件开启了auth 则需要输入密码
mongosh -u root -p 123456
#若想开启用户验证,先使用无验证方式启动 MongoDB
#使用 mongosh 连接后先使用 admin 数据库,进行新用户授权
use admin
db.createUser({user:"root",pwd:"123456",roles:[{role:"root",db:"admin"}]})
#添加后关闭服务器,修改配置文件开启auth,重启即可
db.shutdownServer()开启用户认证
这里添加了管理员用户,并开启了认证系统
mongosh
#若想开启用户验证,先使用无验证方式启动 MongoDB
#使用 mongosh 连接后先使用 admin 数据库,进行新用户授权
use admin
db.createUser({user:"root",pwd:"123456",roles:[{role:"root",db:"admin"}]})
#添加后关闭服务器,修改配置文件开启auth,重启即可
db.shutdownServer()
# 修改配置文件 mongodb.conf文件内容
security:
# 用户验证,默认为disabled,创建管理员账户后修改为enabled
authorization: enabled
# 然后启动mongodb
mongod -f /usr/local/mongodb/etc/mongodb.conf
# 之后使用mongosh进入之后,使用语句与命令都需要鉴权了
mongosh -u root -p 123456MongoDB Compass(GUI)
这是MongoDB官网提供的可视化工具
下载地址:https://www.mongodb.com/try/download/compass
常用的Navicat 在15版本之前并不支持MongoDB,这里使用这个官方的可视化工具来进行操作
Mongodb数据库命令
数据库操作
# 切换数据库,注意:默认是test数据库,这是一个虚拟库,创建用户等操作都需要切换数据库执行
# 如果数据库不存在,则创建并切换到该数据库,存在则切换到该数据库
# 注意,切换之后需要插入数据才会显示在 show dbs 中
use database_name
# 查看所有数据库
show dbs
# 删除数据库
# 使用use切换到要删除的数据,在执行语句
db.dropDatabase()集合操作
# 创建集合
db.createcollection("<collection>")
# 查看所有集合
show collections
# 删除集合
# 成功返回true,否则返回false
# COLLECTION_NAME:集合名称
db.COLLECTION_NAME.drop()
新增
# 插入单条文档文档
# 这里如果集合不存在就会自动创建
db.<collection>.insert(<document>)
# 插入多条文档
db.<collection>.insert([<document>,<document>])查询
# 查询全部数据
db.<collection>.find(<query>)
# 查找第一条数据
db.<collection>.findOne(<query>)
# query 常用写法写法
# 精确匹配
{key:value}
# 多层匹配,用于数据为多层的复杂JSON格式
# 例子:{a:{b:[{c:1},{d:2}]}}
# 知道d的位置,并且条件为d=2
# 从a找到b 语法为 a.b,然后b的数组中找到d=2
# $elemMatch代表数组
{"a.b":{$elemMatch:{"d":2}}}
# AND条件,使用都好隔开即可
{key1:value1, key2:value2}
# OR条件
{
$or: [{
key1: value1,
key2: value2
}]
}
# AND 和 OR 联合使用
{
key1: value1,
$or: [{
key2: value2
}, {
key3: value3
}]
}
# IN 查找
{key:{$in:[value1,value2]}}
# 模糊搜索
# 包含value
{key:/value/}
# 以value开头
{key:/^value/}
# 以value结尾
{key:/value$/}
# 比较操作符
# $gt:大于 | $lt:小于 | $gte:大于等于 | $lte:小于等于 | $eq:等于 | $ne:非等
# 有多种,语法都一致,这里只举例单条件和多条件
# age > 18
{age:{$gt:18}}
# age > 18 AND age < 70
{age:{$gt:18,$lt:70}}
# $type 通过数据类型过滤
{name:{$type:'string'}}
# skip(), limilt(), sort()三个放在一起执行的时候
# 执行的顺序是先 sort(), 然后是 skip(),最后是显示的 limit()。
# Limit 读取N条数据
db.<collection>.find().limit(<size>)
# skip 跳过N条数据
db.<collection>.find().skip(<size>)
# sort 排序
db.<collection>.find().sort({key:value})
# 格式化显示 pretty()
db.<collection>.find().pretty()聚合
# 单一作用聚合
# 忽略查询条件,返回集合或视图中所有文档的计数
db.<collection>.estimatedDocumentCount()
# 返回与find()集合或视图的查询匹配的文档计数
db.<collection>.count()
# 在单个集合或视图中查找指定字段的不同值,并在数组中返回结果
db.<collection>.distinct()
# 聚合管道
# pipeline: 一组数据聚合阶段。除$out、$Merge和$geonear阶段之外,每个阶段都可以在管道中出现多次
pipeline = [$stage1, $stage2, ...$stageN]
# options: 可选,聚合操作的其他参数。包含:查询计划、是否使用临时文件、 游标、最大操作时间、读写策略、强制索引等等
db.<collection>.aggregate(pipeline, {options})
# 常用管道操作符
# $project:AS和列过滤
# 给title和tag这两列重命名并输出这两列
db.books.aggregate([{$project:{name: "$title", booktag: "$tag"}}])
# 对指定字段重命名并剔除不需要的字段
db.books.aggregate([{$project:{name: "$title", booktag: "$tag", _id:0, type:1, author:1}}])
# $match 过滤数据
# 这里例子type:"technology"就是find中的精确查找条件
db.books.aggregate([{$match:{name:"zhangsan"}}])
# $count 计数
# 计数并返回与查询匹配的结果数
> db.books.aggregate([{$match:{name:"zhangsan"}}, {$count: "name_count"}])
# $group 分组
# 语法,这里_id是固定写法 expression:分组字段,field1 被操作字段
# accumulator:操作符
# $avg:平均值
# $first:返回每组第一个文档
# $last:返回每组最后一个文档
# $max:最大值
# $min:最小值
# $push:将指定的表达式的值添加到一个数组中
# $addToSet:将表达式的值添加到一个集合中(无重复值,无序)
# $sum:求和
# $stdDevPop:返回输入值的总体标准偏差
# $stdDevSamp:返回输入值的样本标准偏差
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ...} }
# $limit 限制输出指定数量的文档
db.books.aggregate([{$limit: 5}])
# $skip 跳过指定数量的文档
db.books.aggregate([{$skip: 5}])
# $sort 排序
db.books.aggregate([{$sort: {favCount:-1, 'author.name':1}}])
# unwind 可以将数组拆分为单独的文档。
db.books.aggregate([{$unwind: "$tag"}])
# $lookup 多表关联查询
db.collection.aggregate([{
$lookup: {
from: "<collection to join>", # 同一个数据库下等待被Join的集合
localField: "<field from the input documents>", # 关联表的关联字段
foreignField: "<field from the documents of the from collection>", # 被关联表的关联字段
as: "<output array field>" # 新的字段名称
}
})更新
# 更新要原子操作,<update>一般写为{ $set : { field : value } }
# 更新符合条件的第一条数据
db.<collection>.updateOne(<query>,<update>)
# 更新符合条件的全部数据
db.<collection>.updateMany(<query>,<update>)删除
# 删除符合条件的第一条数据
db.<collection>.deleteOne(<query>)
# 删除符合天骄的所有数据
db.<collection>.deleteMany(<query>)权限认证
mongosh
# 使用mongosh进入后,默认为test虚拟库中
# 需要切换到admin数据库来添加用户
use admin
# 创建管理员用户
db.createUser({user:"root",pwd:"123456",roles:[{role:"root",db:"admin"}]})
# 创建demo集合的管理员用户zhangsan
db.createUser({user:"zhangsan",pwd:"123456",roles:[{role:"dbOwner",db:"demo"}]})
评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果